
タテヨコ変換の基本形①「行列入れ替え+値貼り付け」
エクセルで「タテヨコ変換」をする一番簡単な方法は、「行列を入れ替えてその値を貼りつける」というものです。本稿では『エク達』というウェブサイトに掲載した「タテヨコ変換」のテクニックのシリーズの一環として、「一番簡単な変換方法」を紹介します。ただし、この方法にはさまざまな限界もあるのですが、この点については次回の課題です。
| エクタツは、「エクセル評論家」でもある新宿会計士が、エクセルなどの「オフィス系の汎用ソフト」を使い、誰でも気軽に、かつ安価に、とても迅速かつ正確に仕事をこなす、ビジネスマンとしての基本テクニックを研究するサイトである。 |

本稿では、実務上極めて頻繁に出てくる「タテヨコ変換」の基本形「行列を入れ替えてえの値貼り付け」を紹介したい。とりあえず手っ取り早く「縦横変換」をしようと思うのであれば、この手法が最も簡単である。
実務上、エクセルの「タテヨコ」を変換したいと思うことがしばしば発生する。
たとえば、こんなデータがあったとしよう(図表1)。
図表1 東京都・新規陽性者数の一覧

この図表は、東京都ウェブサイト『新型コロナウイルス陽性患者発表詳細』からダウンロードしたデータをもとに、日付ごと・年齢階層ごとに集計した新規陽性者数の一部を抽出したものだ。
セルを見ていただくとわかるが、行(青枠)が日付、列(赤枠)が年齢階層を意味している。
この点、「年齢階層別」という区分が増える可能性は低いが、行数は無限に増えて行く可能性があるため、シートをこのような形式で作り込むのは、ある意味では当然のことである。
なぜなら、エクセルの場合、列数(つまりヨコ)は限られているが、行数(つまりタテ)は基本的に100万件を超えるデータを展開することができるため、無限に増えて行く可能性があるデータは縦展開するのが基本形である。
ただ、問題は、このままだとどうも加工し辛い、という点にある。
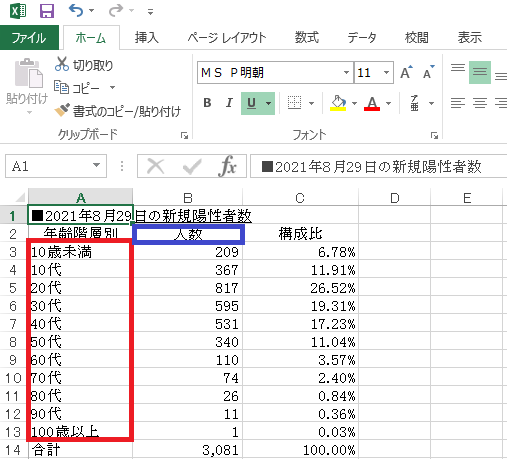
たとえば、実務上は「ある日の新規陽性者数だけを抜き出して、それを年齢階層別にタテに展開したい」というニーズが出てくることもある(図表2)。
図表2 東京都・8月29日における新規陽性者数の一覧と年齢階層別構成比
これを、どのようにして作り込むのが良いか。
いちばん簡単な方法は、「コピー」→「形式を選択して貼り付け」、だ。
具体的には、貼り付けたい値をひとつひとつ見つけ、範囲選択したうえで新たなシートに「Alt+E→S」で「形式を選択して貼り付け」ウィンドウを呼び出し、「値」「行列を入れ替える」の2つのチェックボックスにチェックを入れて「OK」を押すのがいちばん簡単な方法だ(図表3~図表5)
図表3 コピー
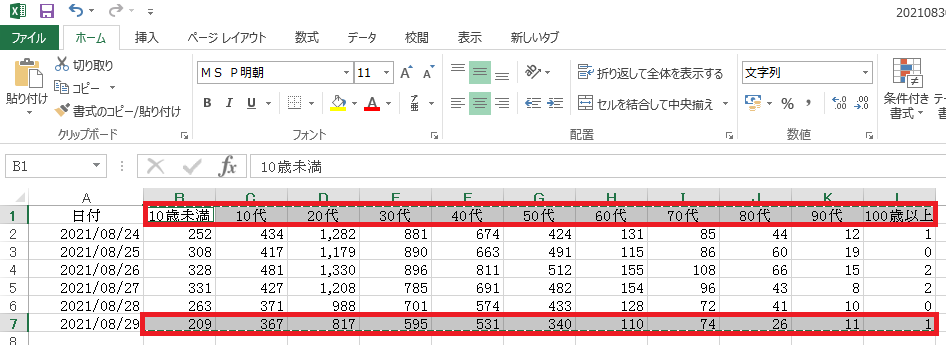
図表4 別シートにて「Alt+E」→「S」を押す
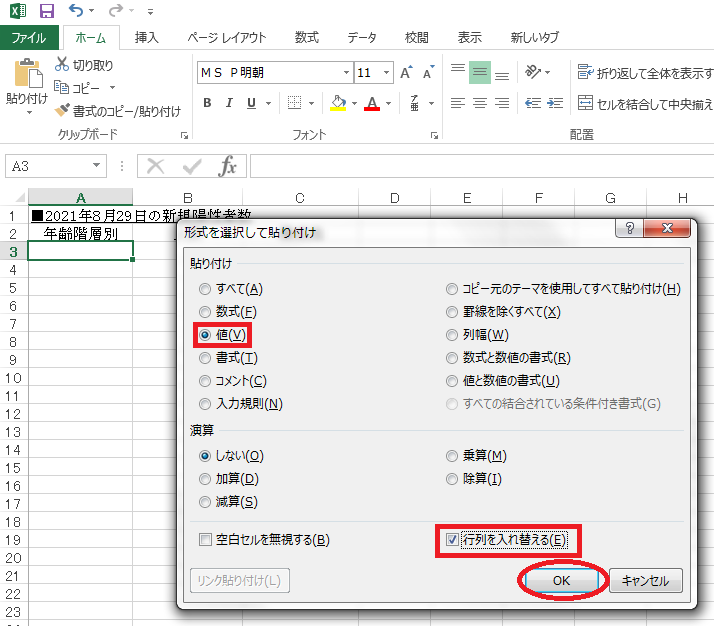
図表5 貼り付けた結果
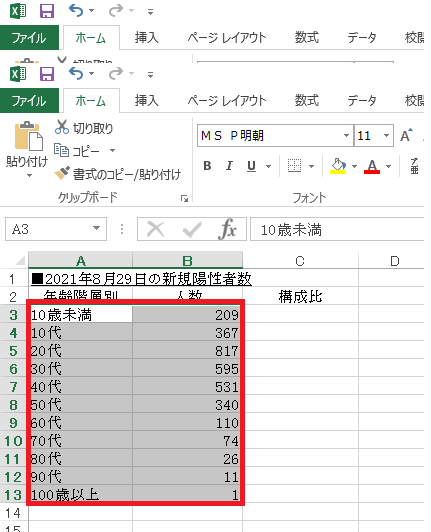
とりあえずは、これが最も手っ取り早いだろう。
ただし、この方法だと、「ある問題」が生じる。その問題とは何か、そしてそれを解決する方法は何か。これについてはあと2回ほど、別稿にて議論したいと思う。
| エクタツは、「エクセル評論家」でもある新宿会計士が、エクセルなどの「オフィス系の汎用ソフト」を使い、誰でも気軽に、かつ安価に、とても迅速かつ正確に仕事をこなす、ビジネスマンとしての基本テクニックを研究するサイトである。 |
本文は以上です。
金融評論家。フォロー自由。雑誌等の執筆依頼も受けています。 X(旧ツイッター) にて日々情報を発信中。 Amazon アソシエイトとして適格販売により収入を得ています。 著書①数字でみる「強い」日本経済 著書②韓国がなくても日本経済は問題ない日韓関係が特殊なのではなく、韓国が特殊なのだ―――。
— 新宿会計士 (@shinjukuacc) September 22, 2024
そんな日韓関係論を巡って、素晴らしい書籍が出てきた。鈴置高史氏著『韓国消滅』(https://t.co/PKOiMb9a7T)。
日韓関係問題に関心がある人だけでなく、日本人全てに読んでほしい良著。
読者コメント欄はこのあとに続きます(コメントに当たって著名人等を呼び捨てにするなどのものは禁止します)。当ウェブサイトは読者コメントも読みごたえがありますので、ぜひ、ご一読ください。なお、現在、「ランキング」に参加しています。「知的好奇心を刺激される記事だ」と思った方はランキングバナーをクリックしてください。
読者コメント一覧
※【重要】ご注意:他サイトの文章の転載は可能な限りお控えください。
やむを得ず他サイトの文章を引用する場合、引用率(引用する文字数の元サイトの文字数に対する比率)は10%以下にしてください。著作権侵害コメントにつきましては、発見次第、削除します。
※現在、ロシア語、中国語、韓国語などによる、ウィルスサイト・ポルノサイトなどへの誘導目的のスパムコメントが激増しており、その関係で、通常の読者コメントも誤って「スパム」に判定される事例が増えています。そのようなコメントは後刻、極力手作業で修正しています。コメントを入力後、反映されない場合でも、少し待ち頂けると幸いです。
※【重要】ご注意:人格攻撃等に関するコメントは禁止です。
当ウェブサイトのポリシーのページなどに再三示していますが、基本的に第三者の人格等を攻撃するようなコメントについては書き込まないでください。今後は警告なしに削除します。また、著名人などを呼び捨てにするなどのコメントも控えてください。なお、コメントにつきましては、これらの注意点を踏まえたうえで、ご自由になさってください。また、コメントにあたって、メールアドレス、URLの入力は必要ありません(メールアドレスは開示されません)。ブログ、ツイッターアカウントなどをお持ちの方は、該当するURLを記載するなど、宣伝にもご活用ください。なお、原則として頂いたコメントには個別に返信いたしませんが、必ず目を通しておりますし、本文で取り上げることもございます。是非、お気軽なコメントを賜りますと幸いです。
コメントを残す
【おしらせ】人生で10冊目の出版をしました
 | 自称元徴用工問題、自称元慰安婦問題、火器管制レーダー照射、天皇陛下侮辱、旭日旗侮辱…。韓国によるわが国に対する不法行為は留まるところを知りませんが、こうしたなか、「韓国の不法行為に基づく責任を、法的・経済的・政治的に追及する手段」を真面目に考察してみました。類書のない議論をお楽しみください。 |
【おしらせ】人生で9冊目の出版をしました
 | 日本経済の姿について、客観的な数字で読んでみました。結論からいえば、日本は財政危機の状況にはありません。むしろ日本が必要としているのは大幅な減税と財政出動、そして国債の大幅な増発です。日本経済復活を考えるうえでの議論のたたき台として、ぜひとも本書をご活用賜りますと幸いです。 |

>「ある日の新規陽性者数だけを抜き出して、それを年齢階層別にタテに展開したい」というニーズ
本題(エク達+行列入れ替え)から外れますがテキストフィルタ的思考でいくと
「2021/08/29」が見つかったら(配列)年齢階層[年齢/10を整数]を+1
…と思ったら元CSVからして年齢じゃなくて年代なのね。じゃあ
第5列が「2021-08-29」だったら(辞書)年齢階層[第9列]を+1
10歳未満 217
10代 371
20代 825
30代 602
40代 535
50代 346
60代 113
70代 75
80代 27
90代 12
100歳以上 1
ありゃ、違ってるけど大体合ってるからご勘弁^^